ocrmac
報稅季來囉!這幾年報稅越來越方便了,連我這個 macOS 使用者都沒什麼申報上的困擾。隨著它的便利性增加,加上「處理日常雜務的 AI 小幫手」被大量採用,這兩年我都很興致勃勃地想要分析國稅局下載回來的 PDF — 試算單、所得清單、扣繳憑單。
身為成熟的大人,我把 AI agent 也當成熟的小幫手看。你大概在職涯中遇過所謂的微管理(micro-management)風格主管 — 帶新進工程師時,連他用哪個套件、變數要叫什麼名字、每一行 code 都要逐字 review,把人當小孩在盯。我才不會用這種方式對待 agent。
我給的目標很簡單:「先把這幾份 PDF 整理成 markdown」。要先說清楚 — 這是我希望整段流程交付的「最終產物」,不是我直接拿去當 prompt 的句子。實際下的 prompt 是流程規範本身(後面會講到的 scope 切法、agent 分工),不是把這句話貼進去就走人。
至於工具,agent 看完幾份 PDF 之後提了 pdfplumber 跟另外兩三個套件,把每個的取捨列給我選。我說它判斷就好,它就選了 pdfplumber 開始跑。這層決定我整段沒插手 — 工具屬於「實作細節」,不是「目標」。
但「不指定工具」不等於「不管流程」。流程結構我反而會管 — scope 怎麼切、agent 怎麼分工,這部分我不放手。例如我會主動把整段分析切成「以頁為單位的整理」跟「以行為單位的數值對照」兩層;scope 一拆,工作範圍自然就切開了。
Agent 分工這邊也有具體約定。我會明確跟 Claude 約好使用 Codex 的方式:指定一個 frontier model 配最高 reasoning effort,要求 Codex 的輸出寫成 Claude 可以直接 feedback 的結構(哪幾條結論、哪幾條疑慮、哪幾條改寫建議),這樣 Claude 下一輪就能把意見吃進去做優化。工具是 agent 的事,scope 切法跟 agent 分工是我的事。
每段交接出來的 artifact,就是我的 checkpoint — 階段一拿到能讀的 markdown、階段二在那份 markdown 上做稅務判讀。中間怎麼接,agent 看著辦。
第一階段交付得很順 — agent 用 pdfplumber 把每頁抽成文字、組成 markdown,看起來很乾淨。準備進到第二階段做稅務判讀的當下,我心裡冒出一個很單純的擔心:
萬一 pdfplumber 把某個數字看錯,後面所有判讀都跟著錯。
這種錯誤不會 raise exception。它會靜悄悄地把 25,305 看成 25305、把 39,994 看成 39.994、把跨欄的兩個 cell 黏在一起變成一串看起來合理但實際拼錯的長數字。如果不另外想辦法 cross-check,根本不會被抓到。
於是我順手問 Claude 跟 Codex:「有沒有什麼 OCR 可以拿來當 second opinion?我用第三方套件偏好能離線跑的,能不上網就不上網。」我本來預期會聽到 Tesseract、EasyOCR、PaddleOCR 這些常見選項。它們列出來的清單裡,前幾個果然都是這些。但有一條讓我停下來:
macOS 13+ 內建的 Vision framework,可以透過
ocrmac這個 pip 套件呼叫。零外部依賴、零雲端、繁體中文支援度高。
我從來沒想過 macOS 自己就有 OCR API。Vision framework 這名字在 Apple 開發者文件裡其實常出現,只是過去我沒往「拿來做文字辨識」這個方向想 — 它就一直靜靜地在 OS 裡待著。
吸引我的點是什麼
ocrmac 是一個非常薄的 Python 包裝,底層就是 macOS Vision framework 的 VNRecognizeTextRequest。讀完文件我才驚覺 — 原來 macOS 預覽程式選取圖片裡的文字、iPhone 相機對著看板就能複製文字 — 這些我天天在用的功能,八成就是這個東西。再翻一輪文件跟網路介紹確認,它的設計目標就是印刷字體辨識(手寫體不是強項)。
它有幾個讓我喜歡的點:
第一,多了一個離線選項。我已經把整份報稅資料丟給 Claude 跟 Codex 來分析了,本來就不是那種「資料絕對不能上雲」的人。但同一件事可以在完全離線的情況下完成,本身就是值得收下的多一張牌 — 以後遇到不適合上雲的場景隨時能拿出來用。
第二,它真的就是個薄薄的包裝。pip install ocrmac 就完事,唯一拉的依賴是 pyobjc(自動裝)。它做的事就是把 Vision framework 暴露給 Python 用 — 真的嫌 pyobjc 麻煩,叫 Claude 幫你寫個 Swift CLI 直接呼叫 Vision 也是同一條路。對比 EasyOCR 那種一裝就拖一個 PyTorch + 1GB 以上模型權重的方案,根本不是同一個量級。
第三,模型已經在那邊了。Vision 是 macOS 內建的系統服務,模型權重不論你用不用都在那邊。ocrmac 只是讓 Python 能吃到這個 API。
但講真的,最大的吸引點不是這三條中的任何一條 — 是「居然有這個東西」這份單純的驚喜。用 Mac 用了這麼多年,OS 裡有 OCR API 這件事,我倒沒有直接聯想到。
簡單易用的範例
from ocrmac import ocrmac
result = ocrmac.OCR(
'page-01.png',
recognition_level='accurate',
language_preference=['zh-Hant', 'en-US'],
).recognize()
for text, conf, bbox in result:
print(f'{conf:.2f}\t{text}')
recognition_level 有兩個選項:fast(快、單字準確度低)、accurate(慢、印刷體準)。對我這種拿來做交叉驗證的場景,當然走 accurate。
language_preference 是 list,順序代表 OCR 嘗試的優先語系。繁中混金額英數的情境,['zh-Hant', 'en-US'] 是 reasonable default。
回傳的每個 element 是 (text, confidence, bbox),bbox 是 [x, y, w, h] 的 normalize 座標(0~1)。要還原 layout 的話,自己用 (y, x) 排序、再用閾值 cluster 成行就好。
場景一:交叉驗證國稅局 PDF
我的 pipeline 變成:
pymupdf把每個 PDF 渲染成 300 DPI 的 PNGocrmac對每張 PNG 做 OCR(accurate,繁中優先)- 從 markdown 抽出所有金額數字,用允許
,、.、空白的 regex 跟 OCR 結果比對
跑完,計算式跟所得清單裡的「原始 PDF 金額」全部被 OCR 抓到。pdfplumber 沒誤讀任何一個數字。
過程中冒出兩類有意思的差異。
第一類是 tokenization 不同。pdfplumber 會把相鄰兩個 cell 的數字黏在一起 — 例如「薪資」跟旁邊「扣繳」連在一起變成一個 13 位數字。OCR 則依視覺空白切開。兩邊資訊量相同,只是切分邊界不同。
第二類是 OCR 自己的小瑕疵。某幾個字型樣本下,Vision 把逗號看成句點 — 39,994 → 39.994。在金額表裡看起來像是把「三萬九千多」誤讀成「三十九點九九四」,但因為這次是 OCR 端的錯,反而證明了 pdfplumber 端是對的。
OCR 對中文罕用字也會偶爾誤判:減 → 淢、抵 → 扺、宅 → 宝、事 → 業 — 但這些在數字驗證情境下完全不影響。
結論很單純:pdfplumber 跟 ocrmac 兩條獨立 pipeline 抽出來的數字完全一致,所以引用到 markdown 的金額可以放心交給 Claude / Codex 去判讀稅務邏輯。
場景二:HSBC 信用卡帳單
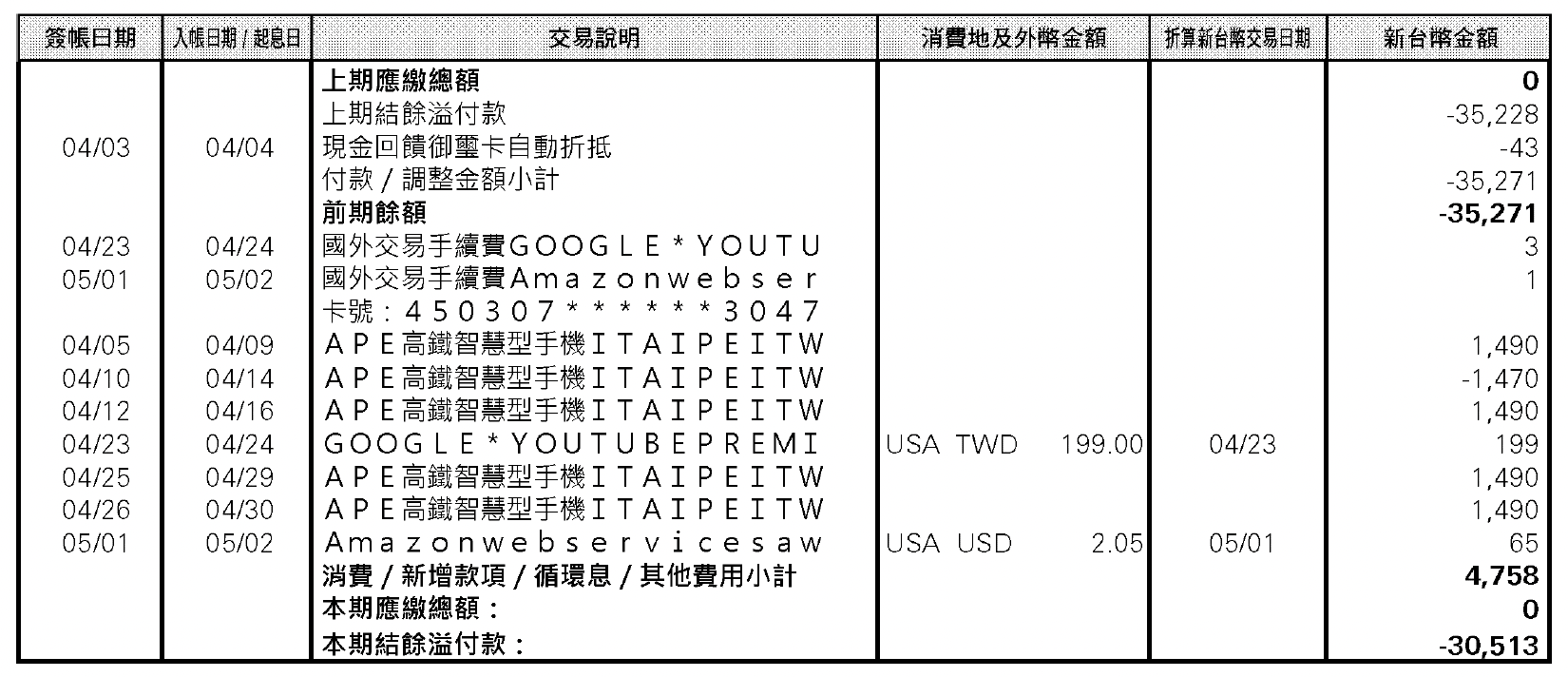
在認識 ocrmac 之後,我想起以前聽人抱怨過的 HSBC 信用卡對帳單 — 大概長上面這樣。順手把同一套 pipeline 套上去試試。pdfplumber 抽出來的內容如下:
HSBC Cash Back Signature Credit Card
2026/05/21 0
2026/05/03 / -35,271 43
100,000 -35,271
( ) 61
4,758
...
04/05 04/09 1,490
04/10 04/14 -1,470
04/12 04/16 1,490
04/23 04/24 USA TWD 199.00 04/23 199
04/25 04/29 1,490
04/26 04/30 1,490
05/01 05/02 USA USD 2.05 05/01 65
一堆裸日期跟裸金額。對照節首的原圖看:表頭(簽帳日期 / 交易說明 / 消費地及外幣金額)不見了,項目標籤(本期應繳總額 / 前期餘額 / 付款小計)不見了,每筆消費的商家名稱也不見了。光看 pdfplumber 的輸出根本不知道哪筆是哪間店刷的。
這個現象我跟 Claude 討論過 — 它的判讀是:這張 PDF 用了某種特殊的字型表示方式,本質上就是把字當圖片內嵌進去。所以對 pdfplumber 而言,表頭、項目名稱、商家描述根本不是文字,只有實際金額才是文字層。
我把這頁轉成圖片餵給 ocrmac,整張 statement 的 layout 全部回來:
- 「簽帳日期 / 交易說明 / 消費地及外幣金額 / 折算新台幣交易日期 / 新台幣金額」這排表頭出現
- 「本期應繳總額」「本期結餘溢付款」「前期餘額」「付款/調整金額小計」這些項目標籤出現
- 「GOOGLE * YOUTUBEPREMI」「Amazon Web Services」「APPLE App Store 高鐵 App」這類商家描述出現
OCR 在這個場景不是來補強 pdfplumber,是另一條獨立把資料抽出來的路。當然你也可以直接把 PDF 餵給 Claude 讓它做 OCR,但只要流程切得乾淨,這一層搭配 ocrmac 就能自己跑完,Claude 留給後面真的有疑問再回頭問就好。
不過 Mac 的 OCR 偶爾也會多出空白,可能跟字距判斷有關 — 「Amazon Web Services」被切成 Ama zon webser、APPLE 在某些字型下被讀成 A PE,跟下一行的中文 description 黏在一起變成 A PE 高鐵智慧型手機 ITAIPEITW。對交叉驗證這種容錯場景沒差,要做精準 parsing 就得另外處理。